DA, DAS, and Blobs — Celestia Lesson 📦🧠¶
🎯 Target: Học từ chính những nhà sáng lập Celestia — Mustafa, Ismail và John về Data Availability (DA), Data Availability Sampling (DAS), và Blobs. Cùng nhau bóc tách Web3 app thật ra là gì, và làm sao Celestia trao cho bạn full-stack control để tự do xây dựng theo cách của mình.
Bài học này sẽ giúp bạn thấu hiểu kiến trúc bên trong của Celestia, đặc biệt là ba yếu tố then chốt: Data Availability, Data Availability Sampling (DAS), và Blobs
Celestia có thể làm cho ứng dụng của bạn ?¶
"In the academic sense, Celestia provides a highly scalable verifiable data availability layer that allows your application to be built in a way users know they have the data needed to audit correctness."
— John, Celestia Labs
Và đây là câu hỏi bạn cần tự trả lời sau buổi học:
“Full-stack control” trên Celestia thực sự nghĩa là gì đối với developer?
Khó khăn chính khi tự triển khai một Layer 1 blockchain so với xây dựng trên Celestia là gì?
Vậy thì thế nào gọi là Full Stack?¶
Full stack control nghĩa là mình có thể tạo applications cho bản thân bằng bất kì ngôn ngữ lập trình nào mình muốn. Bạn cũng có thể tự xây dựng mô hình tạo doanh thu (revenue) cho ứng dụng đó.
Nếu so sánh với Ethereum hay Solana, bạn sẽ thấy mình bị giới hạn ở một số khía cạnh nhất định. Ví dụ, trên Ethereum bạn bắt buộc phải sử dụng EVM và ngôn ngữ Solidity.
Celestia cho phép bạn custom hoá full-stack, tức là từ A đến Z muốn chỉnh gì trong hạ tầng cũng được. Bạn có thể tự build và deploy những ứng dụng unstoppable. Từ tầng consensus (ai xác thực), đến data availability (dữ liệu có sẵn cho ai và như thế nào), tới cả execution environment (VM)
Nói tóm lại bạn có thể hiểu key Features của Celestia nằm ở Modular Design bằng cách các dev có thể tự thiết kế execution layer sao cho khớp với nhu cầu ứng dụng của mình.
Hay nói đúng hơn là Developer Freedom, Điều này mở ra một không gian phát triển cực kỳ linh hoạt.
Vậy data Availability là gì?¶
Data Availability (DA) trả lời cho câu hỏi cực kỳ quan trọng:
“Dữ liệu của block này đã được công bố public hay chưa?”
"It’s the property that, in a blockchain network, the data of the block — meaning the transactions inside the block — has been fully published to the network."
— Ismail, Celestia
Nói đơn giản, Data Availability (DA) là đảm bảo rằng toàn bộ dữ liệu trong một block đặc biệt là các giao dịch bên trong đã được công bố công khai và đầy đủ cho toàn mạng lưới.
Trong các ứng dụng web2 truyền thống, việc xử lý và lưu trữ dữ liệu quy mô lớn là điều tất yếu. Để đáp ứng điều đó, các công ty cloud như AWS, Google Cloud hay Azure đã xây dựng những server warehouses khổng lồ để đảm bảo dữ liệu luôn sẵn sàng cho mọi tác vụ.
Một tình huống tương tự đang diễn ra với blockchain. Nhưng thay vì lưu trữ đơn thuần, blockchain cần đảm bảo rằng dữ liệu giao dịch được công bố một cách công khai và có thể xác minh được. Đây chính là lý do vì sao Data Availability trở thành một trong những điểm nghẽn nghiêm trọng nhất trong việc mở rộng blockchain đặc biệt là với các giải pháp như rollups hay layer 2s.
What is the Data Availability Problem?
Rollups giúp mở rộng quy mô blockchain bằng cách giữ phần dữ liệu trên-chain ở L1, trong khi đẩy phần thực thi (execution) xuống L2 cho nhẹ gánh. Tuy nhiên, vì dữ liệu vẫn cần được post lên L1, nên băng thông dữ liệu của L1 trở thành điểm nghẽn. Muốn scale mạnh, chúng ta buộc phải nâng thông lượng dữ liệu (data throughput) ở L1.
Hãy tưởng tượng flow sau:
- Một publisher post dữ liệu lên mạng, kèm theo một commitment đại diện cho dữ liệu đó (có thể là Merkle root, KZG commitment, etc.), ký hiệu là C.
- Commitment C được lan truyền đến các validator trong mạng.
- Các validator chạy hàm isAvailable(C) để check xem dữ liệu có available không (có đủ, không bị mất, không bị giữ lại…).
Vấn đề ở chỗ làm sao để validator biết chắc là có thể tải hết toàn bộ dữ liệu, mà không thực sự phải tải hết?

Nếu thiếu DA, các block producers hoặc validators có thể xuất bản block mà không công khai toàn bộ dữ liệu bên trong. Điều này tạo ra rủi ro cực lớn gọi là data withholding attack. Khi đó:
- Các node không thể sync lên trạng thái mới
- Ứng dụng có thể bị dừng hoạt động
- Nghiêm trọng hơn, kẻ tấn công có thể rút tiền hoặc thao túng hệ thống
Vấn đề này phổ biến trong các giải pháp L2 như rollups hay validiums. Với rollups hoặc các blockchain layer 2, DA sẽ đóng vai trò cầu nối bảo mật (security anchor) về layer 1 hoặc base layer. Bằng cách publishing full transaction data lên base layer như Ethereum hoặc Celestia, các rollups có thể đảm bảo rằng mọi giao dịch đều có thể được kiểm chứng và khôi phục bất cứ lúc nào.
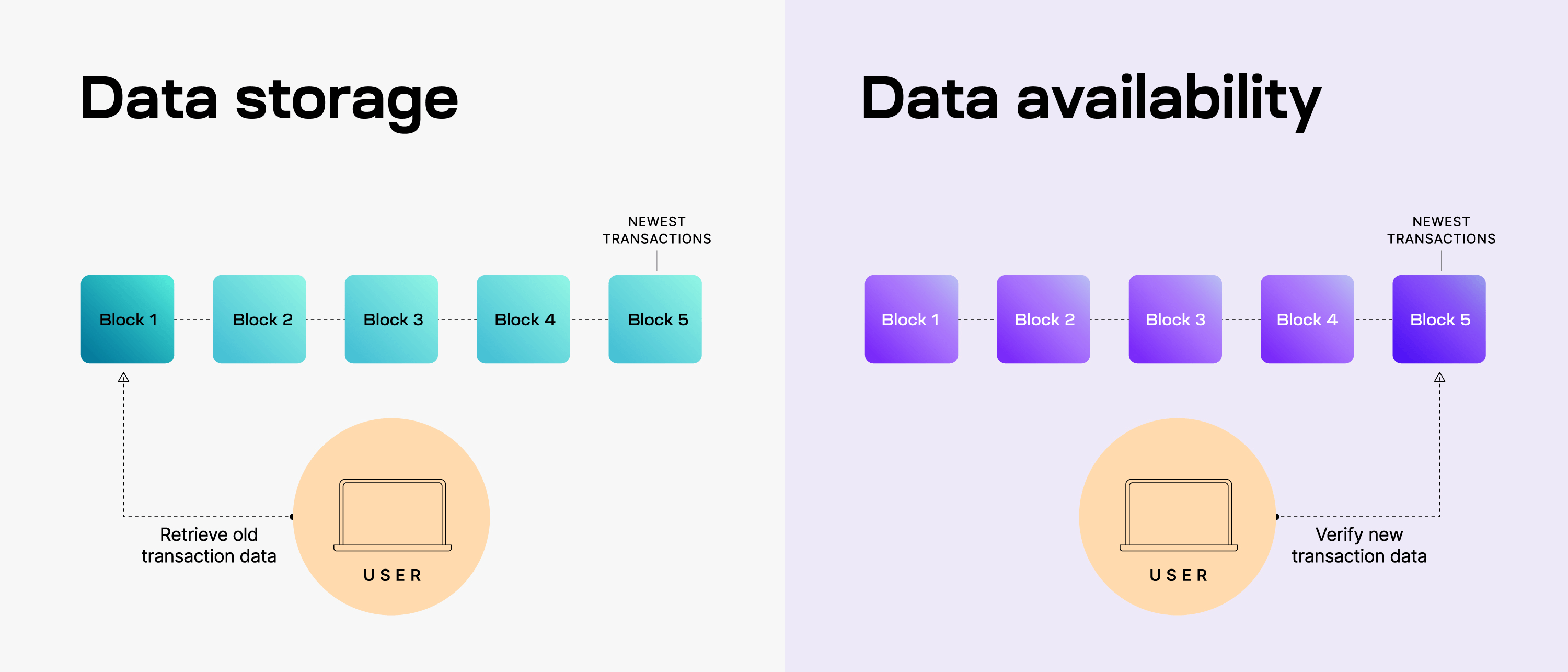
Sự khác biệt giữa Data Storage và Data Availability trong blockchain.
Mục tiêu của data storage là để mình lưu trữ lâu dài để có thể truy cập lại khi cần, kể cả các block cũ. Trong khi Data Availability, người dùng không cần truy xuất quá khứ mà chỉ cần xác minh dữ liệu mới nhất (ví dụ: Block 5).Đảm bảo toàn bộ dữ liệu trong block mới được công bố đúng và đầy đủ tại thời điểm phát hành.
Nói tóm lại thì Celestia cung cấp một DA layer đủ lớn và đủ rẻ để giải quyết điểm nghẽn mở rộng cho các rollup và dApp. Thay vì phải lo gánh nặng chi phí để công bố dữ liệu lên Ethereum hay các L1
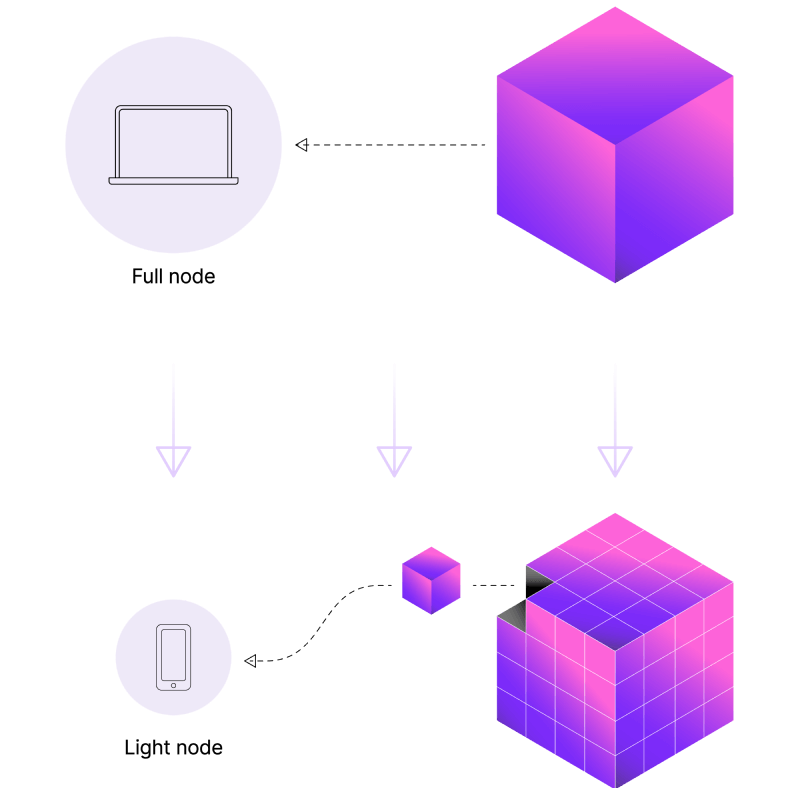
Celestia làm được điều đó nhờ công nghệ Data Availability Sampling (DAS) cho phép các light node (máy nhẹ) vẫn có thể xác minh rằng toàn bộ dữ liệu trong block đã được công bố đầy đủ.
What is data availability sampling?¶
How does Data Availability Sampling (DAS) benefit light nodes on Celestia?
Trước đó bạn sẽ cần hiểu chút về cơ chế đồng thuận của Ethereum, phân biệt được Full node và Light node, Rõ được khái niệm Data Availability hay còn gọi là Data Publicatio trong context là Rollup.
> Data Availability Sampling is a technique that empowers light nodes to have guarantees similar to those of full nodes when it comes to data availability.¶
Data Availability Sampling không dựa vào “niềm tin” vào validator nữa. Data availability sampling (DAS) là một cơ chế giúp light nodes xác minh tính sẵn có của dữ liệu mà không cần phải tải toàn bộ dữ liệu của một block. Light node sẽ thực hiện nhiều vòng sampling ngẫu nhiên. Mỗi vòng sampling chỉ kiểm tra một phần nhỏ dữ liệu trong block. Càng sampling nhiều, node càng tự tin rằng dữ liệu của block đang thực sự tồn tại.
Trong thiết kế blockchain như Celestia, cơ chế DAS giúp light nodes không chỉ đọc dữ liệu hiệu quả mà còn góp phần bảo mật và mở rộng mạng lưới, với chi phí phần cứng rẻ hơn nhiều so với full nodes.
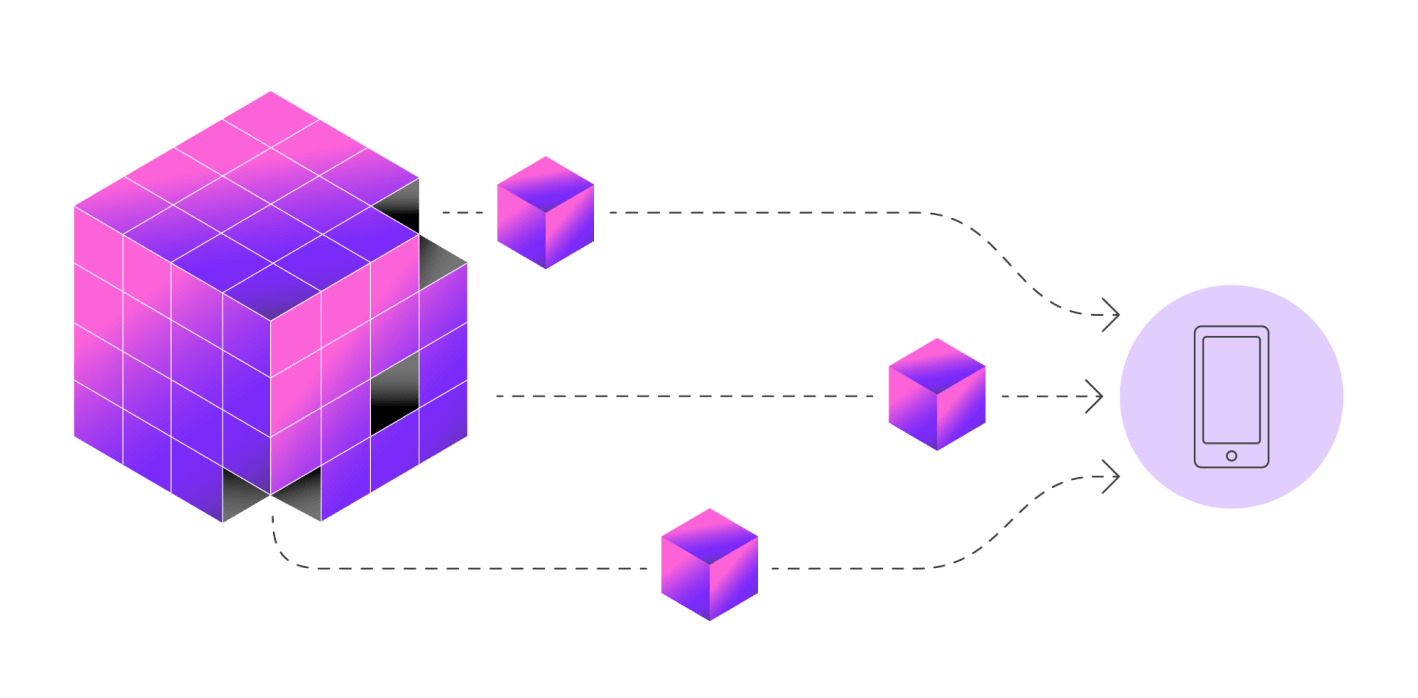
Cách hoạt động của DAS rất thông minh: * Publisher sẽ đăng tải dữ liệu dưới dạng đã được erasure-coded * Các validator sẽ randomly sampling để chọn ngẫu nhiên một số phần nhỏ trong dữ liệu và thử tải về. * Nếu các phần được sample đều tải về thành công thì kết luận rằng toàn bộ block đó có thể được khôi phục, tức là dữ liệu available.

DAS có thể detect được data withholding. Giả sử kẻ xấu (publisher gian lận) định giấu dữ liệu. Để thực hiện được kiểu tấn công này, họ phải giấu hơn một nửa lượng data. Vì nếu chỉ có dưới 50% bị mất, thì các validator vẫn có thể khôi phục toàn bộ dữ liệu gốc từ phần còn lại nhờ erasure coding.
Giờ hãy tưởng tượng validator chạy DAS:
- Nếu dữ liệu bị giấu một phần lớn thì có khả năng sampling sẽ thất bại và DAS phát hiện bất thường.
- Nếu sampling thành công nhiều lần → có cơ sở để tin rằng toàn bộ dữ liệu đã được public

Giả sử một validator thực hiện n lần sampling – tức là thử tải về ngẫu nhiên n mảnh dữ liệu khác nhau.
Nếu kẻ xấu đang giấu hơn một nửa dữ liệu, thì mỗi lần sampling có 50% khả năng trúng ngay vào phần bị giấu.
Vậy xác suất để không phát hiện gì sau n lần sampling sẽ là:
→ (½)^n
Tức là xác suất phát hiện được gian lận (data withholding) là:
→ 1 - (½)^n
🔍 Với chỉ n = 20, xác suất này đã lên tới ~99.9999% – gần như là chắc cú.
Nói cách khác: chỉ cần một light node chạy 20 lần sampling là gần như bắt bài ngay nếu có ai đó định giấu data.
Lợi ích của DAS là Giảm phụ thuộc vào validator và dễ mở rộng quy mô.
Bạn có thể xem giải thích nhanh về Availability Sampling (DAS) explainer trong 5 phút: https://www.youtube.com/watch?v=9Y5rc8OC6yE
Mình có ví dụ. Bạn có hai đồng xu.
- Một đồng luôn luôn ra mặt ngửa (heads)
- Một đồng ra ngửa hoặc sấp (heads/tails) với xác suất 50/50
Giờ mình đưa bạn một trong hai đồng đó, nhưng không nói là đồng nào. Làm sao để bạn biết mình đang cầm đồng nào?
Đơn giản: cứ tung nhiều lần là biết.
Nên càng tung mà thấy toàn ra ngửa, bạn càng có cơ sở tin rằng mình đang cầm đồng đặc biệt đó. Tung khoảng 20 lần, nếu vẫn ra ngửa hoài, thì bạn đã gần như chắc chắn 99.9999% là đang cầm đồng xu gì. Và đây chính là cách Data Availability Sampling (DAS) hoạt động.
Trong blockchain, có hai loại block:
- Block đầy đủ dữ liệu (tương đương với đồng “ra ngửa-only”)
- Block thiếu dữ liệu (giống như đồng 50/50 – có thể lừa bạn bất cứ lúc nào)
Khi một block producer (người tạo block) gửi block cho bạn, bạn cần xác định liệu block này có thật sự đầy đủ dữ liệu hay không. Làm sao biết được? Bạn sampling block đó nhiều lần cũng giống như bạn tung xu.

Data availability committee là gì ?¶
Data Availability Committees (DACs) là những bên được ủy thác (trusted parties) để đảm nhiệm vai trò cung cấp hoặc xác nhận tính sẵn có của dữ liệu (data availability). Trong một số hệ thống, DAC có thể được dùng thay thế cho, hoặc kết hợp cùng với Data Availability Sampling (DAS).
Mức độ bảo mật của DAC phụ thuộc vào cách bạn thiết kế nó. Ví dụ, Ethereum hiện đang sử dụng các nhóm validator được chọn ngẫu nhiên (randomly sampled) để xác nhận data availability cho các light node đây cũng là một dạng biến thể của DAC.
Trong một số mô hình Validium, DAC đóng vai trò là nhóm node đáng tin cậy có nhiệm vụ lưu trữ bản sao dữ liệu ở chế độ offchain. Khi có tranh chấp xảy ra, DAC phải công khai dữ liệu để giải quyết vấn đề. Các thành viên DAC thường phải đăng tải cam kết (attestation) on-chain để chứng minh rằng dữ liệu đã sẵn sàng.
What is the difference between data availability in celestia and data availability committee?¶
It is basicallly is who the participants of nodes attesting to the data availabe.
what is the fundamental difference in trust assumptions between a Data Availability Committee (DAC) and a Data Availability Layer like Celestia?
Trong quá trình phát triển blockchain scalable, một câu hỏi lớn thường được đặt ra: “Liệu chúng ta có thể chỉ chọn một cơ chế đảm bảo tính sẵn sàng dữ liệu hoặc Committee, hoặc Data Availability Sampling (DAS) thay vì phải kết hợp cả hai?”
Câu trả lời hợp lý nhất lại chính là cả hai đều cần thiết. Cùng bóc tách lý do tại sao không nên chỉ dựa vào committee, và cũng không thể hoàn toàn chỉ dùng DAS.
Khi chỉ dùng Committee: bạn chọn ra một nhóm node có trách nhiệm “bảo chứng” rằng dữ liệu trong một block là đã được công bố và ai cũng có thể truy cập. Tuy nhiên, việc đặt niềm tin vào một nhóm người dù là validator, trusted party hay stake-based cũng đồng nghĩa với việc chấp nhận rủi ro. Nếu phần lớn committee đồng ý với một block sai hoặc bị tấn công để làm vậy thì hệ thống không còn cách nào để kiểm tra độc lập xem dữ liệu đó là thật hay giả.
Một vấn đề khác là ngưỡng đồng thuận (threshold): bạn phải đặt ra tỷ lệ bao nhiêu phần trăm committee cần chấp thuận dữ liệu để chain chấp nhận nó. Nếu đặt ngưỡng cao, thì khi số validator online giảm (do lỗi mạng, tấn công, downtime), hệ thống sẽ bị tê liệt. Nếu ngưỡng thấp, thì attacker chỉ cần làm sập một số node là có thể dễ dàng điều khiển phần còn lại để đưa dữ liệu giả vào.
Còn khi chỉ dùng DAS: DAS cho phép bất kỳ ai trong mạng (dù là light node) cũng có thể sampling một phần nhỏ dữ liệu trong block để tự xác minh rằng toàn bộ block đó là hợp lệ. Nhưng DAS, ít nhất là ở thời điểm hiện tại, vẫn là công nghệ rất mới và còn đang phát triển. Nhiều thành phần của nó mới chỉ được đề xuất và thử nghiệm trong vài năm gần đây.
Một bất lợi khác là độ trễ (latency): DAS cần nhiều bước sampling và kiểm tra phân tán hơn so với việc chỉ chờ một số node đáng tin xác minh. Với các hệ thống yêu cầu thời gian xác nhận cực nhanh, committee vẫn có lợi thế về tốc độ.
Blobs¶
Riêng phần này, cảm ơn L2Beat đã minh hoạ giúp mình hiểu sâu hơn về phần này.¶
Để giải thích thì Blobs là dữ liệu mà một rollup công bố lên Layer 1 hoặc lớp Data Availability (DA) của nó. Dữ liệu này bao gồm các giao dịch L2 đã được “cuộn lại” (rolled up), kèm theo một số metadata liên quan.
Blobs được giới thiệu như một loại giao dịch mới trên Ethereum thông qua đề xuất EIP-4844, với mục tiêu chính là tăng khả năng mở rộng cho rollups.
Điểm đặc biệt là blobs không tồn tại vĩnh viễn mà được lưu trữ một cách tạm thời trên Beacon Chain của Ethereum, đủ lâu để đảm bảo tính khả dụng dữ liệu (data availability), nhưng không cần giữ lâu dài như các dữ liệu lưu trữ truyền thống.
Trên Celestia, blobs là dữ liệu do người dùng gửi lên, nhưng không làm thay đổi trạng thái của blockchain (non-state-altering data).
Mỗi blob gồm hai thành phần chính:
- Phần dữ liệu gốc (raw bytes): một đối tượng nhị phân chứa nội dung thực tế do người dùng cung cấp.
- Namespace: định danh cho ứng dụng cụ thể mà blob này thuộc về. Điều này cho phép nhiều ứng dụng khác nhau cùng sử dụng chung Celestia mà vẫn tách biệt dữ liệu một cách rõ ràng.
Với thiết kế này, Celestia không chỉ đóng vai trò là DA layer có khả năng mở rộng, mà còn là data publishing layer cho các ứng dụng modular: từ rollups, games, đến các AI agent hay ứng dụng mạng xã hội phi tập trung.

Tất cả dữ liệu được đăng lên Celestia dưới dạng blob sẽ được chia nhỏ thành các phần có kích thước cố định, gọi là shares.
Mỗi blob được sắp xếp thành một ma trận kích thước k × k, với k hiện tại là 64, tức là mỗi blob gồm tổng cộng 4096 shares.

Các hàng và cột của ma trận shares sẽ được mã hoá bằng kỹ thuật erasure coding, nhằm tạo thêm dữ liệu dư thừa phục vụ cho việc khôi phục (recovery).
Kết quả là, ta có một ma trận mới kích thước 2k × 2k, tức 128 × 128 shares, đủ để hỗ trợ Data Availability Sampling (DAS) hiệu quả.
Để đảm bảo tính xác minh (verifiability), toàn bộ ma trận sau khi erasure-code sẽ được cam kết (committed) bằng một cấu trúc cây Merkle đặc biệt có tên là Namespaced Merkle Tree (NMT).
Khác với Merkle tree thông thường, trong NMT:
- Mỗi node trong cây không chỉ chứa hash của con mà còn lưu thêm phạm vi namespace bao trùm tất cả node con của nó.
- Điều này cho phép các ứng dụng truy vấn chính xác blob thuộc namespace riêng của mình, mà không cần xử lý toàn bộ cây.
- Đồng thời vẫn giữ nguyên các tính năng như inclusion proof hay range proof tương tự Merkle tree truyền thống

Cuối cùng, từ các root của từng hàng và cột trong ma trận erasure-coded, Celestia tính toán ra một data root duy nhất, gọi là availableDataRoot.
Đây chính là gốc của cây Merkle tổng thể, dùng để cam kết toàn bộ dữ liệu đã được chia nhỏ, mã hoá và tổ chức trong block. Root này sẽ được đưa vào block header, đóng vai trò như chứng thực (commitment) cho toàn bộ dữ liệu dạng share trong ma trận.
Nhờ đó, bất kỳ share nào trong ma trận đều có thể được chứng minh (prove) là một phần hợp lệ của block data, bằng cách dẫn ngược lên từ leaf → row/column root → availableDataRoot.

Để đảm bảo data availability (Dữ liệu thực sự tồn tại và ai cũng có thể truy cập), Celestia cho phép light node (kiểu node nhẹ, không cần lưu toàn bộ dữ liệu) thực hiện một kỹ thuật gọi là sampling trên một ma trận dữ liệu siêu to khổng lồ cụ thể là ma trận 2k x 2k (chính xác là 2,048 x 2,048 ô dữ liệu).
Mỗi light node sẽ random chọn vài tọa độ bất kỳ trong ma trận mở rộng đó, sau đó yêu cầu dữ liệu tương ứng cùng với Merkle proof (bằng chứng dữ liệu không bị chỉnh sửa) từ full node. Hiện tại, để “chốt kèo” rằng một block dữ liệu có sẵn, mỗi light node phải thực hiện ít nhất 16 lần sampling. Nếu block có vấn đề (thiếu dữ liệu), với xác suất 99%, light node sẽ phát hiện ra điều đó trong quá trình sampling. Ta có thể đọc kỹ hơn trong paper Fraud and Data Availability Proofs
